.png)

一、前置问题:Prometheus 是什么?为什么要用它?
在深入 Prometheus 之前,需要先明确运维中的两个核心概念:监控与告警。
1.1 监控是什么?
在运维领域,监控是指通过持续观测服务器、应用或系统的运行状态,将其行为(如 CPU 使用率、请求延迟、错误率等)以时序数据形式采集并存储,从而帮助运维与开发人员发现性能瓶颈、异常行为或潜在风险。
1.2 告警是什么?
告警是监控的自然延伸。当监控系统检测到指标超出预设阈值(如磁盘使用率 > 90%、服务不可用等),会通过邮件、短信、企业微信、钉钉或 Webhook 等方式主动通知相关人员,以便及时响应和处理。
1.3 Prometheus 简介
Prometheus 是一款开源的系统监控与告警工具包,最初由 SoundCloud 开发,现为 CNCF 毕业项目之一。它采用拉取模型采集指标,支持多维数据模型与强大查询语言 PromQL。
1.4 为什么选择 Prometheus?
1.5 Prometheus 整体架构
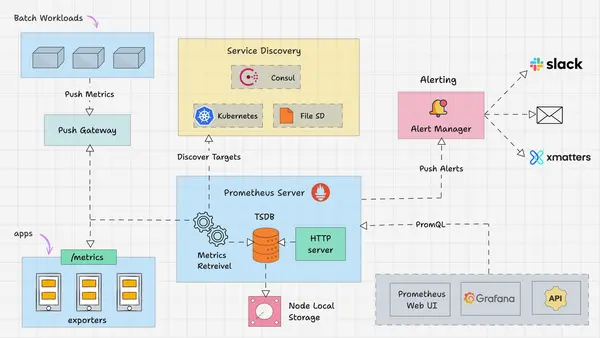
从架构图可以看出,Prometheus 的工作流程可分为以下五个关键步骤:
安装与配置
服务发现(Service Discovery)
指标采集(Metrics Collection)
数据展示(Visualization)
告警(Alerting)
二、安装与配置
Prometheus 的部署模式随基础设施演进分为两大类。
2.1 传统部署方式(服务器原生安装)
在物理机或虚拟机上,通过以下方式安装:
下载预编译二进制文件
使用 systemd 管理进程
通过 apt / yum 等包管理器安装
典型路径:
适用场景: 传统 IDC、非容器化环境,或作为联邦集群中的中心节点。
2.2 集群内部署(容器化 / Kubernetes)
使用 Helm Chart(如 prometheus-community/kube-prometheus-stack)或 Prometheus Operator 部署。
2.3 混合架构场景
在实际生产环境中,常采用联邦(Federation) 或远程写(Remote Write) 模式,将集群内的 Prometheus 采集数据汇聚到中心节点,实现统一监控视图。
本文后续步骤以服务器原生安装为例。Kubernetes 内的部署请参考下文"Kubernetes Prometheus 监控部署方案"。
2.4 原生安装步骤
根据操作系统选择对应版本(Linux / Windows / macOS)
解压到任意目录即完成安装
主要配置文件为
prometheus.yml,位于根目录
示例配置:
# 全局配置
global:
scrape_interval: 15s # 默认抓取间隔
evaluation_interval: 15s # 规则评估间隔
# 告警管理器配置(需单独部署 Alertmanager)
alerting:
alertmanagers:
- static_configs:
- targets: []
# - alertmanager:9093
# 告警规则文件
rule_files:
# - "rules/alerts.yml"
# 抓取任务配置
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
labels:
app: "prometheus"启动命令:
# Linux / macOS
./prometheus --config.file=prometheus.yml
# Windows
.\prometheus.exe --config.file=prometheus.yml启动后访问 http://localhost:9090 即可进入 Prometheus Web UI。
三、服务发现(Service Discovery)
3.1 为什么需要服务发现?
静态环境:使用
static_configs手动指定监控目标(如192.168.1.10:9100)即可。动态环境(Kubernetes、Docker Swarm 等):Pod 重建、扩缩容、滚动更新会导致 IP 和端口频繁变化。若每次变动都手动修改配置,显然不现实。
3.2 Prometheus 支持的服务发现机制
3.3 重点:kubernetes_sd_configs
在 Kubernetes 中,最常用的是 kubernetes_sd_configs,它通过连接 Kubernetes API Server 自动发现以下资源:
关键时间点:
配置示例:自动发现所有节点
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
target_label: address
replacement: '$1:9100' # node_exporter 默认端口
- source_labels: [__meta_kubernetes_node_name]
target_label: instance该配置自动将每个 Node 的 IP 拼接为 IP:9100 作为抓取目标。
四、指标采集:Pull 模型与 Exporter
Prometheus 默认采用 Pull 模型,主动从目标拉取指标。
由于大多数系统(如 MySQL、Redis、Node)本身不暴露 Prometheus 格式的指标,因此需要 Exporter 作为"翻译器"进行适配。
4.1 示例:node_exporter
node_exporter 是官方提供的 Exporter,用于采集 Linux 主机的系统级指标(CPU、内存、磁盘、网络等)。
部署方式(Kubernetes DaemonSet):
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v1.10.2
ports:
- containerPort: 9100
hostPort: 9100
args:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/)
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys关键说明:
hostNetwork: true+hostPort:使 node_exporter 绑定到 Node 的 9100 端口挂载
/proc和/sys:获取主机内核信息每个 Node 上运行一个实例
Prometheus 抓取配置(配合 kubernetes_sd_configs):
- job_name: 'node-exporter'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):.*'
replacement: '${1}:9100'
target_label: address
- source_labels: [__meta_kubernetes_node_name]
target_label: instance配置完成后,Prometheus 会自动发现所有节点,并从 http://<NodeIP>:9100/metrics 拉取指标。
五、数据展示:Grafana
Prometheus 自带的 Web UI 仅支持简单查询,可视化能力有限。Grafana 是业界标准的时序数据可视化工具,与 Prometheus 无缝集成。
5.1 集成步骤
部署 Grafana(容器或二进制方式均可)
添加 Prometheus 数据源,URL:
http://<prometheus-host>:9090导入仪表盘
官方提供大量模板,例如:
六、告警(企业级实践说明)
当前主流的企业级实践中,告警配置与管理工作已逐渐从 Prometheus 原生 Alertmanager 转移至 Grafana Alerting 或统一告警中心。因此本文暂不深入 Prometheus 原生告警的配置细节,后续可单独展开。